

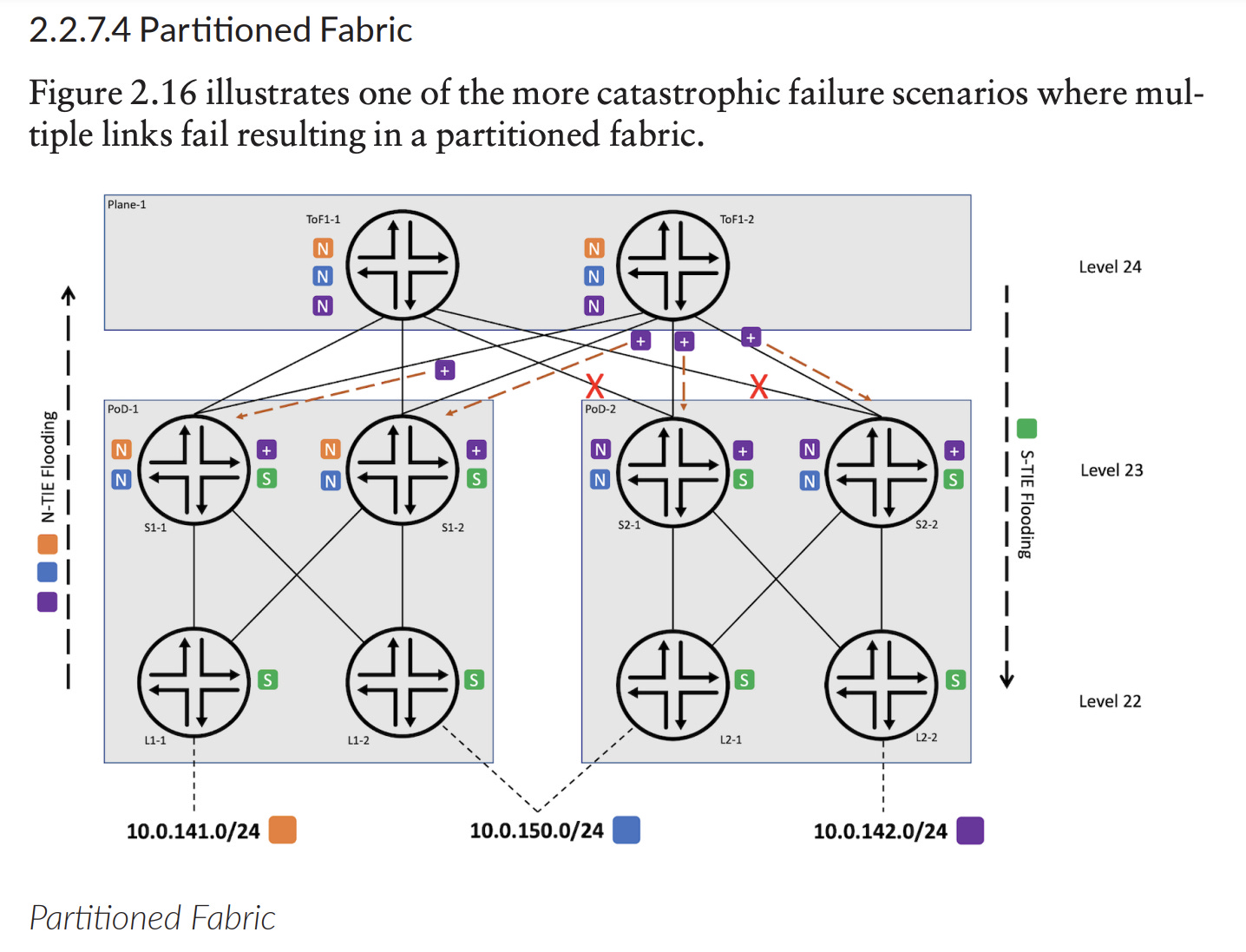
Image Source: Juniper Networks, DAY ONE: ROUTING IN FAT TREES (RIFT)
Introduction
Routing in Fat Trees (RIFT) is a new approach to routing created in response to challenges that were being experienced in dense, regular, topologies in large-scale data centers. To achieve the goals, more information was required, which meant new information elements, such as Topology Information Elements (TIEs) and Link Information Elements (LIEs). This leads to, from a standard English perspective, delicious sentences like:
“Local node has received a valid LIE from the remote node.”
I really hope the authors of Juniper’s new DAY ONE: ROUTING IN FAT TREES (RIFT) pdf/book had as much fun writing that sentence, as I did reading it.
Valid LIEs? Many decades ago, I was traveling with a friend, through the backwoods of Georgia, in the middle of the night, and the only thing on the radio was a preacher, who asked his listeners this question “Can you trust your conscious”. I was immediately reminded of how much my brain hurt listening to the preacher’s challenge, when I read about “valid LIEs”. I’m going to assume the IETF does not get its working group documents reviewed by marketing people, or people like me who were raised chronically Catholic.
All joking aside, RIFT is of course one of the most interesting initiatives currently evolving in the world of routing. No doubt, increasing real-world experiences will lead to unforeseen issues, and I do wonder if it threatens the very premise of end-to-end source routing - SR overlays notwithstanding, I will leave that for another article.
If we take the position of casting a technical & skeptical eye on the new “shiny, shiny” (James Bensley), two top of mind questions for me, have been a) does RIFT provide benefits for small networks, including the coming wave of edge clouds, and b) does it provide benefit in 5G aggregation networks. Those questions merely reflect things I have been, or might be, involved in. Questions from readers will vary. In the rest of the article, I am going to lift quotes from the pdf/book and use them as the basis for discussion.
Discussion
“Since physical interaction is required to cable devices together in the correct manner, human error will always be a factor. However, in densely connected IP fabrics, identifying when something is mis-cabled is challenging, tedious, and time consuming, requiring engineering staff to validate the interface and protocol operation. The validation itself is also error prone and can cause collateral damage when examining optical cabling and transceivers…RIFT requires very minimal configuration in that you only need to configure which devices are considered Top-of-Fabric. If the devices downstream of the Top-of-Fabric nodes are cabled correctly they will automatically provision. Adjacencies won’t form on mis-cabled or mis-configured links.”
In a landscape dominated by the great protocol wars/camps, this is an issue that is not likely to get top billing. However, it is the kind of issue that routers should have been working on a long time ago. Maybe in a world of smaller processors and 32-bit operating systems, there were bigger fish to fry, but for decades, it was as if the routing ecosystem had automated the discovery of topology/reachability and then declared victory. An end state of true, reliable, autonomous zero touch provisioning is a desirable end state, and in this context, RIFT is definitely a welcome initiative.
“Automation does help to make this dramatically easier, but reliable automation can be expensive to develop and maintain, especially as scale requirements increase. And automation works best when nodes are already reachable, which requires a working IGP.”
To me, this is one of the more interesting “philosophical” issues of the coming decade in networking. How much “automation” can and should be done by a centralized system, all by itself, vs how much should really be done by the network. I feel that RIFT is arguing that a good deal should be done by the network itself. The fact that Jeff Tantsura, whose day job is building intent-based automation systems, is the chair of the IETF RIFT WG, and an enthusiastic supporter of RIFT, kind of puts an exclamation mark on that point, for me.
Intent-based management systems will arguably always understand intent/policy better than the network, but in terms of what is actually going on in the network, the source of truth is the network itself. In addition, fast, local actions, including ZTP, are desirable. People involved in network strategy/architecture have to really sit with, and digest this point, IMO.
“Building truly stateless services unaffected by infrastructure failures is incredibly difficult and ultimately shifts the problem to messaging systems holding service state. These messaging systems become very fragile if the delay and loss characteristics of the underlying network are not nearly perfect.”
The fact that this statement exists, implies this has already been an issue with hyperscalers and perhaps other environments as well. I suspect it is going to be an issue in Edge clouds, from discussions I have already had.
For a decade or more, the narrative has been that networking is such a small part of IT/datacenter spend, that it is relatively unimportant. Well apparently, there are some nuances to that narrative, especially when the network can undermine the core value proposition/business model. Not all problems in IT are because of the network, but some are.
‘Since RIFT has been designed from day one with the vision of supporting servers being part of the underlay or “Routing on the Host” (ROTH), deploying it on servers is possible and addresses all the concerns above.’
I won’t repeat all the arguments about security air gaps, and fragile multi-path layer 2 technologies, but the bottom line is, a reasonable argument is made for the benefits of having servers’ part of the layer 3 routing domain, but it has to be done in a scalable way. This is one of the benefits of RIFT that deserve some attention, and perhaps industry discussion as well. Today we have standards progressing for MPLS labels via ARP, discussion about server-to-server SR, and classic IP routing. Will be interesting to see how this all plays out.
“In short, RIFT maintains only the absolute minimum routing information that is required to establish reachability in the fabric. This may allow a greater reduction in hardware costs and better ROI the further south you go in the network, com- pounded by the fact that leaf nodes are the most ubiquitous.”
RIFT’s approach of default routing into the fabric, and link state advertisements from top of fabric to spine, is interesting, and perhaps the heart of where protocol war/debates will start. Link state flooding is a known issue at scale, and a number of mitigations are being considered. If that specific issue is the only problem under consideration, then maybe RIFT is not the answer for everyone. However, RIFT is attempting more than that, for example some of the issues above.
Whenever I see or hear of an RFI/RFP for an access router, in a SP network, requiring enormous amounts of routing functionality and scale, for a router that has cost pressures and only two alternative paths, sometimes only one, I tend to stop and wonder why.
Obviously there are options that open up when access routers can do it all, and there is this force in the direction of pushing BGP peering further into the network, but still, I feel architects/designers have to really consider what is ultimately their needs: many, many, low cost, simple, reliable routers in access/aggregation, or other considerations.
RIFT authors are thinking along similar lines for data centers (and perhaps more). What does a top-of-rack router/switch really need to do? What are the TOR router’s real information requirements? As TOR is a battle that has already been lost to ODMs in some hyperscalers, and perhaps more broadly over time, there is not a catastrophic downside for vendors, today, to just focus on what customers really need in that part of the network.
“BGP on the other hand suffers from slower convergence behavior known as path hunting. This is where, as a failure propagates through a network the path will become longer and longer until traffic is ultimately blackholed. This is made much worse in the case of a more specific prefix failing where a larger aggregate exists…RIFT eliminates this problem with its disaggregation mechanism, since a prefix is only disaggregated when failures occur, troubleshooting becomes much easier compared to OSPF, IS-IS, or BGP.”
To the best of my knowledge, this is a problem that mostly occurs when a leaf is not fully meshed to all planes, so a spine advertising an aggregate, may not remove that aggregate, just because a single leaf is not reachable, leaving the spine continuing to receive packets for a leaf it cannot reach - black hole. I am not sure if this problem occurs in all topologies. However, it is an interesting issue, and the development of finer grain exception advertisements (positive & negative - don’t route here) without removing the previous aggregate, does provide optionality.
“One of the reasons Clos and fat-tree topologies have become the de facto standard for IP fabrics is the advent of a significant increase in traffic between servers within the data center (East/West) as opposed traffic leaving or entering the data center (North/South). Spine/leaf variants make it possible for each service’s traffic flows to traverse the shortest path, meet capacity needs, and remain highly resilient to failures.”
While RIFT authors emphasize that RIFT is not just for CLOS, it is also clear that some of the pressures of large-scale CLOS led to RIFT.
SPs are thinking through whether CLOS applies to 5G aggregation networks. I’m not sure. If 5G aggregation networks do CLOS just because it is cool and they want to look like hyperscalers, that is probably the wrong reason. Will the traffic in 5G aggregation networks be mostly East/West or mostly North/South? Clearly there will be edge compute that has East/West traffic. Overall, though, it is an issue I need to dig into more. I suspect just by the nature of what SPs do, there will be significant North/South traffic. Are there advantages to SPs from using consistent, regular, highly redundant, CLOS networks? Perhaps, as long as they are easy to manage, and maybe RIFT helps there as well.
At some point, the “routing community” needs to decide if it is wise to make one protocol the “protocol to end all protocols.” Is a single solution the right answer for all problems? Or is it better to move back towards developing multiple parallel protocols to support different use cases? This criticism may not apply to operators building their private implementation of BGP for use on their DC fabrics—but these kinds of implementations are few and far between.
As few readers will read this far (TL;DR) ;-) I am going to throw the most controversial issue in last :-) RIFT proponents are clear they are not anti BGP for the underlay, and indeed have been supporting those networks for years. OTOH, to achieve the kind of autonomy RIFT designers are seeking, may require significant modifications to BGP, and those modifications may have unintended consequences for the larger Internet/ network interconnection, which is the main/primary design point of BGP. That may be an issue for the IAB, IESG, IETF, and broadly speaking the community as a whole, but it may not be the top of mind concern for the average network manager trying to assess whether RIFT adds value to what she is doing.
Conclusion
The goals of RIFT are ambitious, so some new stuff to consume. Previous knowledge of path/route vector protocols and link state protocols accelerate the learning curve on RIFT, but there are new things as well. For networks with chronic problems, the learning curve may have more urgency than for others, like all new “shiny, shiny”, positive feedback loops will be informative (other network managers having good experiences).
There is clearly a set of pressing concerns for large-scale CLOS/regular fabrics. That said, all network managers should want to get to networks that have true ZTP, optimal routing state advertisement and storage, cooperative autonomy between the network and centralized systems (augmented routing), a balance between aggregates and fine-grain advertisements (positive and negative)/less black holing, and more secure/robust server-to-server networking.
There is significant implementation detail in Juniper’s new day one book. Some of it Juniper specific. Some of it relating to an open source implementation. Enough to dive into, and get a sense of what implementing RIFT might look like. Enjoy!
Your blog here is so good made me think a bit so here's more. 1. The True LIEs acronyms are fully intended, it's actually quite deeply rooted in psychology/brain physiology and how people learn that led me to choose acronyms that way ;-) 2. SR & RIFT: yes, SR is a great technology to start in the leaf as overlay as e.g. SRoUDP and terminate on DCI, we see lots of that. RIFT will not preclude SR in the fabric but frankly, I have to see a use case for SR in IP fabric underlay I believe in (footnote: it's overkill for error triangulation e.g.). 3. yes, I paid lots attention to the gripes of people actually cabling fabrics, lots interesting things like "I just want to know WHO as in switch/port is on the other side" led to lots stuff you find in the protocol design. 4. Automation/Intent is _great_ and super valuable when we talk about "service monitoring & provisioning". IGP is just standard pipes, e'one standardizes on laying them same way by now (that's your other argument, we see lots of CLOS now in access/sattelite access/core form factors, you name it". The reason is that CLOS is imply the most effective way to interconnect crossbars, we know that since 50s and the math is very hard to argue with. So, use controller to provision service which is unique to every network (since that's the produce you sell while fabric is just "ram chips") but using controller to provision your IGP while you have no IGP is kind of interesting but really unnecessary exercise AFAIS. 5. RIFT is AFAIS the simplest solution to pull servers into underlay with minimal resource consumption and once you multi-home them L3 all the service migration and other headaches go away. True multi-home L3 is not just "download the default route", it needs proper dealing with failures upstream or "on the other side" as well so simple static 0/0 is good neough if you think "blackholing is ok, we have pagers for that" only. And yes, you can always find a more complex way to solve the same problem ;-) 6. I don't follow your argument really how RIFT design impacts BGP, it's just another way to get your IGP next-hop really but that would be an interesting discussion.